
You're about to live through a story that every engineering leader eventually experiences. It's a story about growth, about success, and about an invisible tax that quietly erodes everything you've built. It starts with velocity. Then it ends with waiting.
In systems thinking, there's a pattern called "Shifting the Burden", identified by Peter Senge in "The Fifth Discipline", where organizations repeatedly apply symptomatic solutions that provide quick relief while the fundamental problem grows worse. When build times slow down, companies buy faster hardware. When throughput drops, they hire more developers. When coordination fails, they rewrite everything in a different technology. These solutions feel productive because they're tangible and immediate. But they're treating symptoms, not the disease. And with each symptomatic fix, the organization becomes more dependent on them, while losing the capability to solve the underlying problem.
This is that story. And it costs companies millions before they realize what's happening.
The Metric That Rules Everything
There's a number that strongly signals whether your engineering organization is thriving or drowning. It's not lines of code. It's not story points. It's not even bugs per release. It's merge throughput: how many code changes successfully make it into your main branch each day. This metric tells you how fast features reach your customers, how quickly bugs get fixed, how rapidly you can respond to market demands. It's the heartbeat of your engineering organization.
And here's what most engineering leaders don't realize until it's too late: as your team grows, this number can actually go down. Sometimes dramatically. Let me show you what's coming.
Phase 1: The Lone Wolf
You launch your startup on a Tuesday. You're a solo founder who codes, armed with Claude and GitHub Copilot as your pair programmers. No team. No process. No friction. You push straight to main. Multiple times a day, every day. There are no code reviews because there's nobody to review with. There are no merge conflicts because you're the only one committing. There's no CI pipeline slowing you down because every bug that slips through goes straight into the weekly release to your five beta users who are just happy the app exists.
With your AI coding assistants writing boilerplate and suggesting implementations, you're moving at a pace that would have seemed impossible five years ago. The merge throughput is pure: one developer, zero overhead. This is the golden age. This is what velocity feels like.
But your app is growing. Users are signing up. And one bad commit ships a critical bug in your weekly release because there was no safety net. That's when you realize: pure velocity without quality control is just recklessness in disguise.
Phase 2: Adding Safety Nets
You set up GitHub Actions. You create a branch called "develop" and promise yourself you'll only merge to main after tests pass. You hire your first engineer, Marcus, who's also using AI coding tools to write code faster. Now when you want to ship a feature, you open a pull request. The CI kicks off, running tests and linting. Marcus reviews your code. Then it merges. When Marcus ships code, you review. The cycle repeats.
You're still moving fast, though not quite as fast as before. Once or twice a week you run into a merge conflict because you both touched the same file, but it's quick to resolve. Occasionally a test fails randomly, and you just rerun the CI. Your team of two has added some overhead per commit. But you've also stopped shipping bugs in your weekly releases. It's a worthy trade-off.
The app is growing. Revenue is growing. You raise a seed round and decide it's time to build a real team.
Phase 3: The Team Multiplier
Six months later, you have five engineers. Everyone has AI assistants helping them write code. The roadmap is ambitious. The team is talented. The codebase has tripled in size. You'd expect throughput to multiply with the team. But that's not what happens.
Li opens a PR in the morning. It sits waiting for review because you're in meetings and Marcus is deep in his own feature. Hours later, you finally review it. You request changes. Li makes the updates, but the CI takes longer now because the test suite has grown. And when it finishes, there's a merge conflict because Marcus merged something that touched the same service. Li resolves it, reruns CI. By afternoon, one commit finally lands.
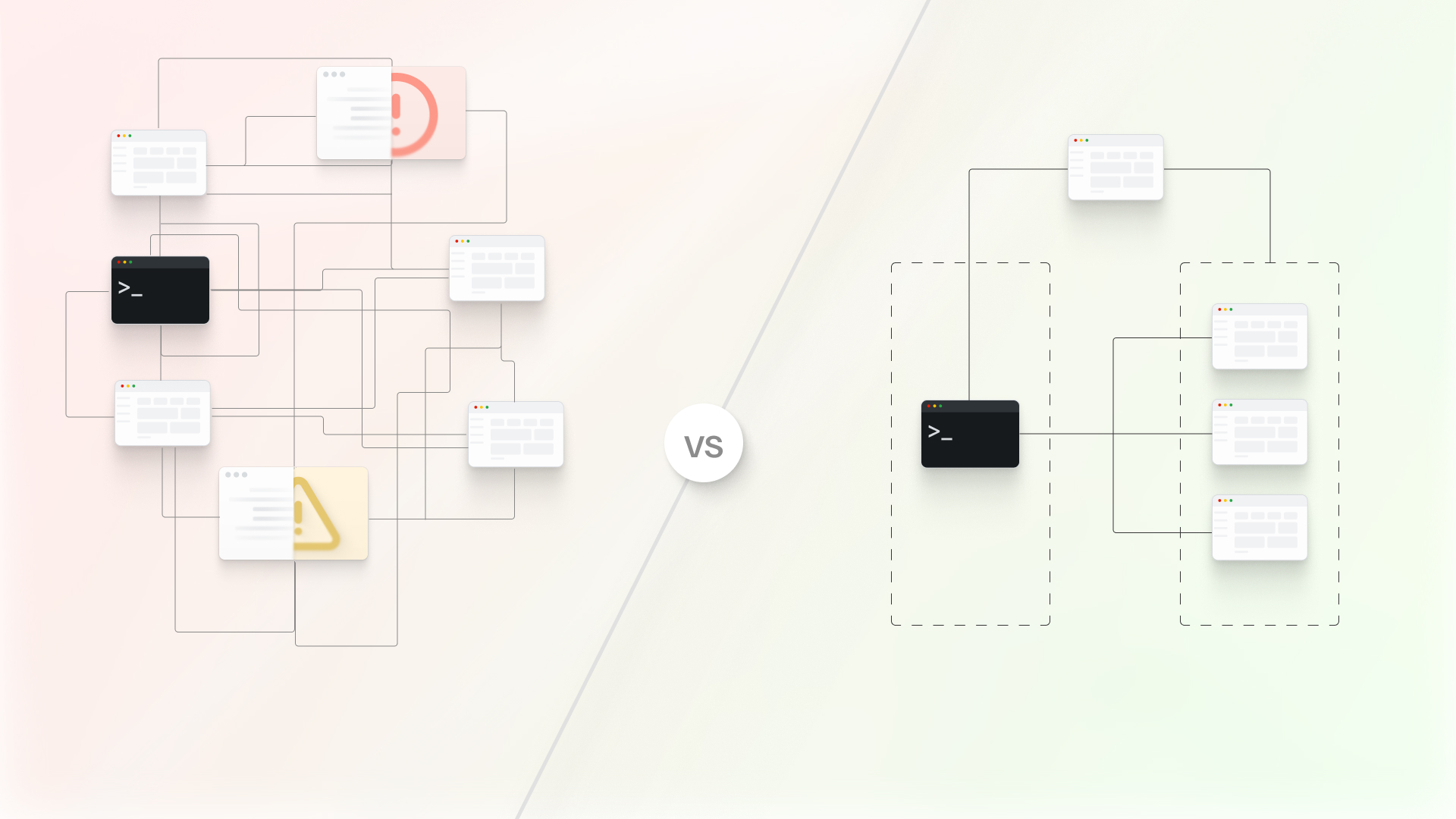
This happens to everyone, all day long. PRs sit in review queues. Merge conflicts happen frequently now that five people are touching overlapping code. The CI occasionally has a flaky test, and nobody's quite sure which test it is, so they just click "retry." Many PRs come back with requested changes, adding another round trip. The throughput has grown, but nowhere near what you'd expect from adding three more engineers.
And then there's the CI bottleneck. Your provider asked you to estimate how many runners you'd need. That works when your workload is predictable, but it's not. Nobody's is. During peak hours, PRs pile up waiting for available runners. Your team sits idle, watching the queue grow. The provider is just leaking the pain of hosting Mac minis to you. They can't absorb your elastic demand because they don't operate at the scale you need. You're not blocked by budget. You're blocked by infrastructure that can't keep up.
You hired three more people and throughput improved, but not nearly as much as you expected. This isn't what growth is supposed to look like.
Phase 4: The Complexity Wall
Two years in, your mobile team has grown to 30 engineers. Everyone is shipping code, everyone has AI tools making them more productive than ever, and the feature velocity should be incredible. But something's wrong.
The CI now takes 15 to 25 minutes. Nobody remembers who wrote half the tests in the suite. Flaky tests fail frequently, and debugging which test is flaky wastes hours. PRs sit for hours waiting for review because everyone is context-switching between their own features, meetings, and multiple PRs in their queue. When reviews finally happen, many come back with requested changes. More waiting. More CI runs. Merge conflicts happen constantly. When someone finally resolves a conflict and merges, they hold their breath hoping nobody else merged while the CI was running. If they did, back to square one.
You're paying millions in engineering salaries and getting a fraction of the output you should. Leadership asks why feature delivery has slowed down. You don't have a good answer.
Phase 5: The Brute Force Trap
Your team comes up with a plan. Three plans, actually. Each one sounds reasonable in isolation, but none of them address the root problem:
Option 1: Faster Machines "We'll upgrade to the beefiest CI runners GitHub offers," he says. Sixteen cores instead of four. It'll cost hundreds of thousands per year, but it'll cut the CI time in half. Your team calculates the improvement: modest at best.
Option 2: More People Someone suggests hiring more developers to "parallelize the work." Another million-plus in salary. But you've learned the math by now. More people means more conflicts, longer review queues, even slower CI. Throughput might not move at all. It might even go down.
Option 3: Technology Rewrite A CTO from your previous company suggests you rewrite everything in React Native. "No compilation step," he says. "Way faster iteration." The rewrite would take months, cost your entire team's focus, and millions in opportunity cost. And at the end, you'd inherit a new set of problems:
A brittle foundation built on constantly-evolving packages. The ecosystem moves fast, breaking changes are common, and keeping dependencies up to date becomes a perpetual maintenance burden. What works today might require rewrites tomorrow.
A massively expanded security surface. Instead of relying on platform APIs maintained by Apple and Google, you now depend on hundreds of npm packages, each with their own maintainers, each a potential entry point for supply chain attacks.
Platform features become harder to access. Every time iOS or Android releases a new API, you wait for someone in the community to write a bridge. Native features that should take hours now take days or weeks, assuming someone builds the bridge at all.
Performance optimization becomes the default state. Instead of focusing on building features, your team spends cycles debugging why lists scroll slowly, why animations drop frames, why the app uses too much memory. The abstraction layer adds overhead that you constantly fight against.
But you'd still have the same coordination problems.
You pick the faster machines because it's the cheapest mistake. Throughput improves slightly. You're paying hundreds of thousands a year to make a small dent in the problem. You know you're treating symptoms, not the disease. The disease is that you're building and testing everything, every time, for every change, no matter how small. But you don't know what else to do.
Phase 6: Smart Optimization
But there's an elephant in the room. Something that would be cheaper than all three options, and would have a dramatically better impact.
What if you didn't compile and test everything every time? What if you could diff the changes to be selective about what to compile and what to test? When Li changes the authentication module, why are you rebuilding dozens of other modules that didn't change? When someone touches a networking utility, why are you running the entire test suite instead of just the tests that actually depend on that code?
Then you talk to an engineering leader at another company who faced the same wall. "We integrated Tuist," he says. "Binary caching and selective testing. Changed everything." The idea is simple: only rebuild what changed, only test what's affected, and share the cached results across your entire team and CI.
Your team spends one week integrating Tuist. You set up binary caching so when Li changes the authentication module, the other modules use cached builds from the last time they were compiled. You implement selective testing so the CI only runs the tests affected by the change, not the entire suite. The first PR after the optimization merges in minutes instead of an hour.
Your CI time drops dramatically. The queue disappears because jobs finish faster. Review time drops because fast feedback means reviewers can stay in context. Merge conflicts drop because the faster cycle time means less overlapping work. The merge throughput more than doubles.
You're still paying the same in engineering salaries. But now you're getting dramatically more output. The efficiency more than doubles. You've unlocked millions in value. The investment was a fraction of one engineer's salary per year for Tuist and one month of implementation time. The payback period was measured in days, not years.
What Just Happened
Let's trace your journey. At one developer, you had pure efficiency. Zero overhead. At two developers, you maintained most of that efficiency. At five developers, efficiency dropped noticeably. At thirty developers, efficiency crashed. You were getting a fraction of the output you should from your team size.
After optimization, with the same thirty developers, efficiency more than doubled. Not perfect, but dramatically better than where you were. And here's the key insight: you optimized workflows first, not hardware. Instead of spending hundreds of thousands per year to make your waste happen slightly faster, you spent a fraction of that to eliminate the waste itself. The hardware approach provided marginal gains. The workflow approach transformed the organization.
Why Most Companies Get This Wrong
Here's the pattern we see repeatedly: companies optimize in the wrong order and waste millions before discovering the right solution.
Let's take a typical scenario: a 30-person mobile team with 20-minute CI times. Each developer waits for CI roughly three times a day. That's 60 minutes per developer per day spent waiting. Across the whole team, you're wasting the equivalent of 5 full-time engineers just waiting for builds. At an average salary of €140K, that's €700K per year in wasted time.
"But they can just work on something else while waiting," you might think. This misses the real cost. Research shows it takes an average of 23 minutes to regain focus after an interruption. When CI breaks your flow three times a day, you're not losing 20 minutes per build. You're losing 20 minutes of waiting plus 23 minutes getting back into flow state. Task switching reduces productivity by up to 40%. The actual cost isn't the wait time. It's the shattered attention, the broken flow states, the mental fatigue from constant context switching. That 60 minutes of visible waiting becomes 2+ hours of lost productivity.
The typical sequence looks like this:
Year 1: Faster Hardware. Team hits slow CI times. Leadership approves €300K annually for the fastest runners available. CI time drops from 20 minutes to 12 minutes. Modest improvement. Everyone celebrates. But wait times per developer only drop from 60 to 36 minutes per day. The team is still building and testing everything, just slightly faster. Value unlocked: roughly 2 FTE worth of time (€280K). But it costs €300K per year. You're barely breaking even.
Year 2: Hire More People. Throughput is still terrible. Leadership hires 10 more developers at €1.4M annual cost. But more developers means more CI contention, longer queues, more conflicts. Wait times actually increase to 75 minutes per day. Instead of gaining capacity, you've made the problem worse. The coordination overhead grows faster than the output.
Year 3: Technology Rewrite. Someone suggests rewriting everything in React Native. "No compile times!" The rewrite takes six months, costs the entire team's focus, and millions in opportunity cost. At the end, you've traded one set of problems for another. The coordination problems are identical. They just happen in a different language.
Total spend over three years: €3M+ in direct costs (hardware, new hires, rewrite), plus countless hours of engineering time. Throughput improved marginally.
The alternative sequence that actually works:
Month 1: Implement binary caching and selective testing. When a developer changes one module, the others use cached builds. When someone touches code, only the affected tests run, not the entire suite.
The result: CI time drops from 20 minutes to 4 minutes. Wait times drop from 60 to 12 minutes per developer per day. That's 48 minutes saved per developer per day. Across 30 developers, you've saved 4 FTE worth of time annually. At €140K average salary, that's €560K in recovered value. The cost? Roughly €20K per year. Not by building faster, but by building less. Only what changed. Only what matters.
The Choice
This story is every company's story. The only question is which chapter you're in, and whether you'll choose to optimize the right thing.
The difference isn't just the value, though that's dramatic. The difference is that one approach treats symptoms while the other fixes the disease. Faster hardware makes waste happen faster. More people amplify coordination overhead. Better workflows eliminate the waste entirely.
Optimize workflows before hardware. A faster machine makes your waste happen faster. A better workflow eliminates the waste. One costs significantly more and provides modest improvements. The other costs a fraction and transforms the organization.
Ready to see what this looks like for your team? Talk to us about how Tuist can help you scale, or get started and see the difference in days, not months.
